.svg)
.svg)


You’ve already heard about Yanny vs. Laurel, but here’s a perfunctory intro in case you have made the intelligent decision to not pay attention to this.
There’s a video with a recording of a man saying the word “Laurel” for vocabulary.com. Some people hear “Yanny” when they listen to it, others hear “Laurel,” a handful hear both, and everyone is freaking out. Twitter data shows 47% of people on the site hear “Yanny” and 53% hear “Laurel.” Even CBS cares about this for some reason. In this post, I’m going to examine the Great Yanny / Laurel Debate from an audio science and psychoacoustics perspective, because I’m procrastinating on my real work.
I started by ripping the audio from the original video from reddit. I dropped it into Ableton so we could get a better look at the audio’s spectrogram. In case you’re not familiar with audio spectra, we’re looking at a visual representation of all the audible frequencies of a given audio signal.

“Yanny” “Laurel”
As you can see, the spectrogram of this audio is quite noisy. Amplitudes of the signal’s individual frequency bands are more randomly distributed throughout the spectrum – clear evidence of an informal phone or laptop mic recording. There are a few important things to note here, but the most obvious abnormality is that the signal drops off sharply around 6 kHz. We’ll get into that later, but first let’s talk about noise.
When we listen to noisy audio, our brains work harder to identify patterns and interpret what we’re hearing. Since the “ee” vowel sound we hear in “Yanny” lives in a higher frequency range, and the “o” and “oo” sounds of “Laurel” live in a lower range, we’re more likely to hear one or the other if we’re predisposed to hear a higher or lower frequency range. Which frequency you are predisposed to hear depends on a few factors, including your listening environment, age, and lifestyle.
As we age, our stereocilia (the tiny hairs in our ears whose responses to changes in air pressure allow our brains to process these changes as sound) begin to lose their potency. Older people have lost more cilia in the course of their lifetimes than younger people, so it stands to reason that they have less ability to hear higher frequencies, but it is also very possible to destroy these cilia, even at a young age. According to Ethan Siegel at It Starts With A Bang,
“The most sensitive cilia are the ones closest to the outside: only a tiny vibration is needed to set them in motion. These are also the most easily destroyed. So when you do things to damage your hearing like go to rock concerts without earplugs, listen to your headphones or stereos too loudly, fire a gun without protective gear, or have your “friend” scream in your ear, these sensitive cilia get destroyed.”
Young people are therefore more likely to hear “Yanny,” while older people and frequent irresponsible enjoyers of loud music might gravitate towards “Laurel.” The miracles of modern audio processing tools, however, allow us to correct for this. Let’s take a listen to the clip with a low pass filter at 1 kHz:
Sounds a little more like “Laurel,” right? That’s because the high frequency vowel sounds of “Yanny” have been de-emphasized by the filter. Let’s try it with a high pass filter instead:
If you’re older or have experienced plenty of loud noises without ear protection (or both), hopefully you were able to hear “Yanny” in the high-passed audio file. If you’re a younger or more hearing-conscious person, maybe the low pass helped you understand how anyone could say it’s actually “Laurel.”
Let’s go back to that original spectrogram. Recall that there was a lot of noise and a significant reduction in the audio signal at 6 kHz – an interesting clue. To investigate further, I downloaded the original recording of “Laurel” from vocabulary.com, which happens to be a 128kbps mono .mp3 file.

“1DF66F7GBFQ2U.mp3”, from vocabulary.com
Next, I examined the source audio file’s spectrogram:
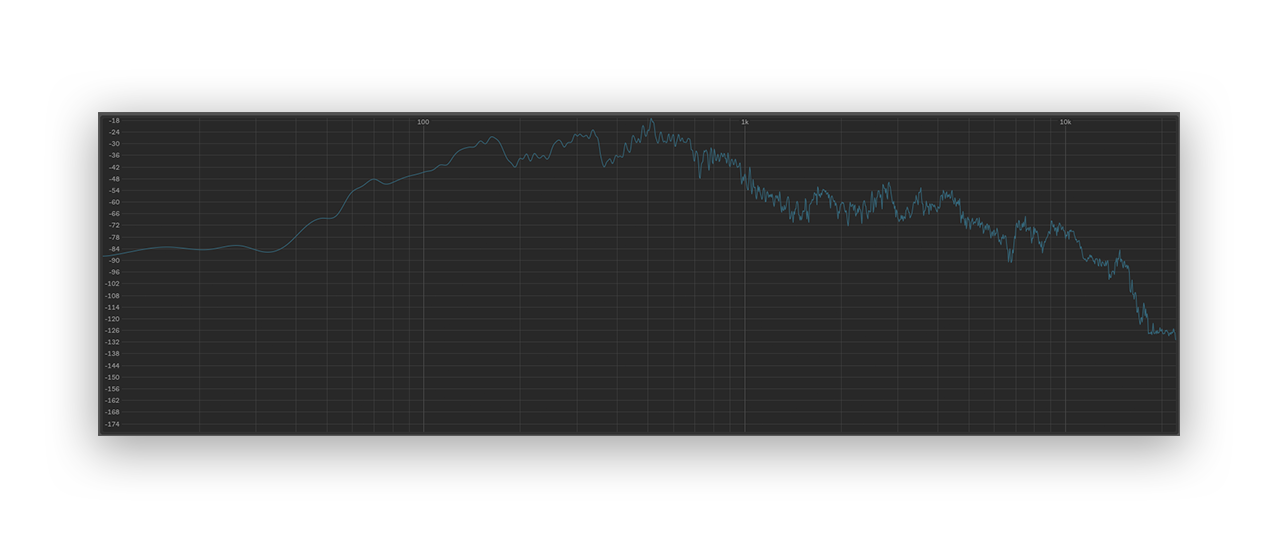
This is similar, but not identical, to the audio ripped from Twitter. Note that there is no dropoff at 6 kHz – in fact, the audio information remains consistent with normal human speech all the way up to around 16 kHz.
.mp3 files are “lossy,” meaning that they produce a less faithful reproduction of the original audio but achieve a smaller file size through a specific set of compression techniques known as “codecs.” We’d expect to see a reduction in signal at 16 KHz due to the compression applied to audio by the codec when it encodes audio into a .mp3 file at 128kbps. However, the steep filter at 6 kHz cannot be explained away by .mp3 compression – there must be another reason for the frequency dropoff at 6 kHz from the reddit audio. This dropoff might be attributable to a low-quality mic; the reddit user probably recorded playback of the vocabulary.com audio through their phone or built-in laptop mic.
It’s clear that there’s a significant difference between the reddit user’s recording and the original file from vocabulary.com, which may be attributable to mic noise or a poor quality recording environment. We don’t have to guess; we can prove the differences between the two files. If they were identical, we’d expect the audio from reddit to phase cancel with the original version.
Regardless of the noise’s source, we’ve shown for sure that there is extra noise present in the file, and that this noise colors our perception: if the phase cancellation had occurred (meaning that the files were identical), the output would be silent.
Let’s talk about one final wrinkle – the noise on your end, likely from your listening environment.
If you’re listening through speakers, especially nicer speakers with a defined low end, it could color your perception of the audio, especially when combined with the noise already present in the original file. By the same token, using headphones might make it easier to focus on different frequency ranges present in the signal.
I used Audacity to denoise the file in an attempt to increase clarity. Give it a listen on different setups if you can:
It’s harder to know how this will affect your perception, but anecdotally, the removal of noise has reinforced our Splice employee guinea pigs’ initial takes. Has this been your experience? Do you hear one or the other, despite being old or young? We’d love to hear your reactions in the comments below or @splice.
May 17, 2018

